Actualité de l'audiovisuel
Actualité de l'audiovisuel
Le MIT a développé une IA qui peut voir…
L’IA devient de plus en plus importante pour résoudre des problèmes difficiles, mais elle n’a pas la capacité de comprendre le contexte jusqu’à présent.
Le contexte est tout. L’IA peut résoudre de nombreux problèmes, et elle est de plus en plus importante pour le fonctionnement de l’informatique moderne. Mais cela reste un peu un instrument contondant, et un obstacle important à surmonter est la capacité de l’IA à comprendre la relation contextuelle entre les choses.
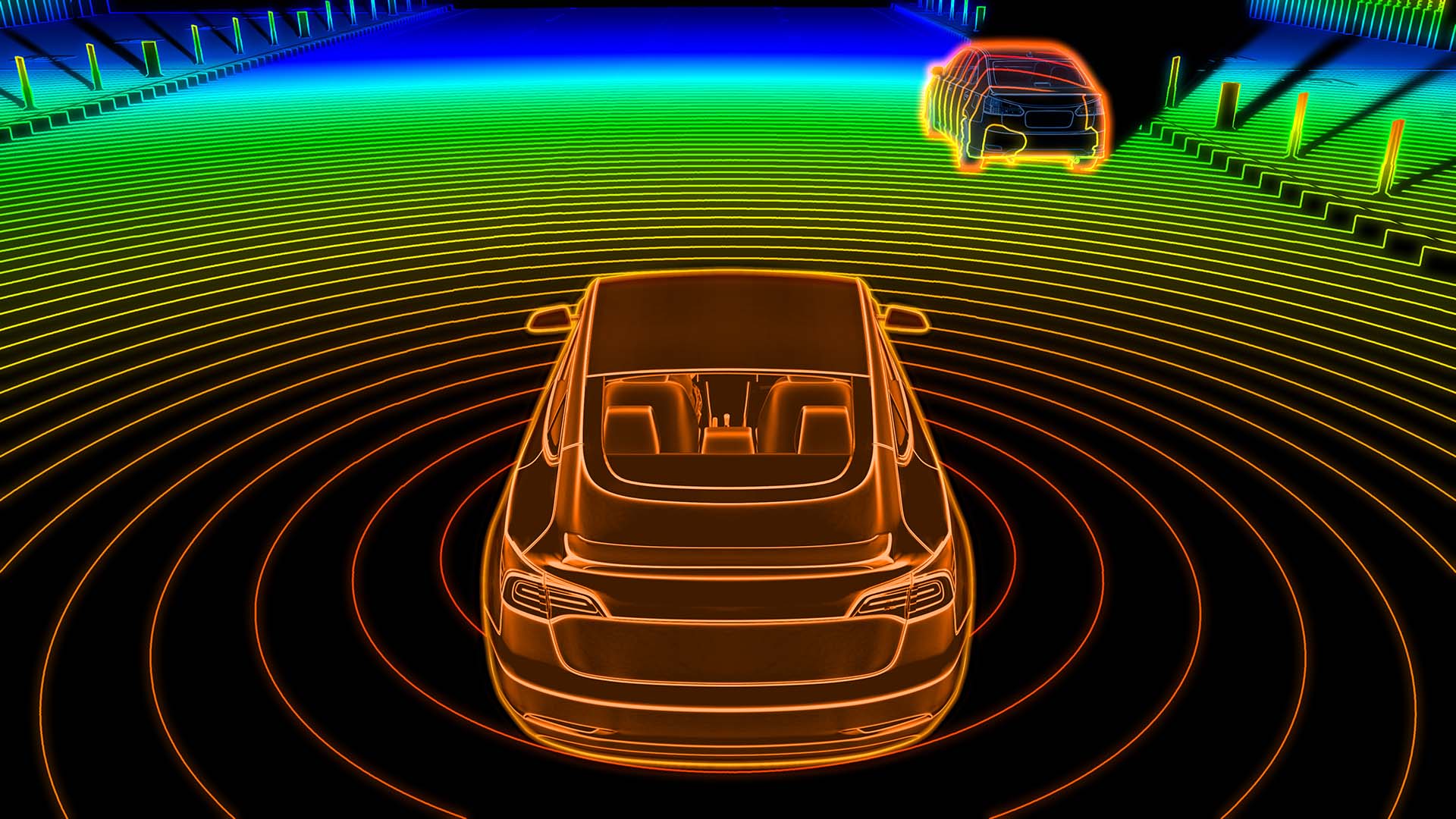
Imaginez un objet comme une bouteille ou un verre assis sur une table. Jusqu’à présent, l’IA pouvait identifier la bouteille ou le verre, mais elle ne comprenait pas que ces objets étaient physiquement sur le dessus de la table. Au lieu de cela, dans le monde du système d’IA, ce sont simplement des objets qui sont côte à côte, et pour autant qu’il sache que la bouteille ou le verre flotte au-dessus de la table.
Le MIT a développé une IA, appelé 3DP3 pour comprendre ces relations contextuelles en utilisant la programmation probabiliste. Par exemple, le système peut contre-vérifier les objets détectés par rapport aux données d’entrée pour voir si les images enregistrées à partir d’une caméra correspondent à une scène candidate.
La technique de programmation probabiliste donne effectivement au système du « bon sens » et permet au système de tenir compte des erreurs qui pourraient survenir avec une approche d’apprentissage en profondeur.
Le système peut déduire la relation entre les objets d’une scène concernant les objets mentionnés ci-dessus. Par exemple, si un bâton est appuyé contre un mur, le système pourra « raisonner » que le bâton est dans la position où il est car il est en contact avec le mur.
Cela signifie que le système peut placer plus précisément des objets dans l’espace 3D et mieux comprendre la relation complexe entre eux.
Anciens concepts
Le système a été développé en s’appuyant sur un concept d’IA précoce qui suppose que la vision par ordinateur est « l’inverse » de l’infographie. C’est-à-dire que l’infographie génère des images basées sur la façon dont une scène est représentée, mais la vision par ordinateur est l’inverse de cela. Les chercheurs ont repris ce concept et ont rendu la technique plus apprenable et évolutive.
« La programmation probabiliste nous permet d’écrire nos connaissances sur certains aspects du monde d’une manière qu’un ordinateur peut interpréter, mais en même temps, elle nous permet d’exprimer ce que nous ne savons pas, l’incertitude. Ainsi, le système est capable d’apprendre automatiquement à partir des données et de détecter automatiquement lorsque les règles ne tiennent pas « , explique Cusumano-Towner, l’un des chercheurs.
Étonnamment, le système nécessite beaucoup moins de ressources que les techniques d’apprentissage en profondeur. Par exemple, alors que l’apprentissage en profondeur peut nécessiter des milliers d’images d’entraînement en entrée, l’approche 3DP3 peut en apprendre davantage sur une scène en utilisant seulement cinq images sous des angles différents. Il apprend ensuite la forme de l’objet et estime le volume qu’il occupe.
Le chercheur principal Nishad Gothoskar a déclaré: « Si je vous montre un objet sous cinq perspectives différentes, vous pouvez construire une assez bonne représentation de cet objet. Vous comprendriez sa couleur, sa forme, et vous seriez capable de reconnaître cet objet dans de nombreuses scènes différentes, «
Les chercheurs ont comparé le modèle 3DP3 à plusieurs systèmes d’apprentissage en profondeur et ont découvert que le nouveau système les surpassait à chaque fois, utilisant beaucoup moins de ressources.
Mais ils ont également découvert que le système 3DP3 pouvait fonctionner en harmonie avec une IA à apprentissage profond en corrigeant les erreurs. Par exemple, un modèle d’apprentissage en profondeur peut prédire qu’un objet flotte au-dessus d’un autre. Mais 3DP3 peut regarder la scène et « réaliser » par un raisonnement probabiliste que cela est physiquement impossible et corriger la relation d’objet.
Les chercheurs disent que bien qu’il y ait un long chemin à parcourir avant que cela puisse être fait en temps réel, leur objectif ultime est d’amener le système à comprendre ces relations à partir d’une seule image.
Cela pourrait être une évolution importante dans le contexte de la navigation de véhicules autonomes ou pour des robots qui pourraient avoir à manipuler des objets, tels que celui conçu pour le nettoyage ou l’organisation dans un environnement complexe.